Содержание
Михаил Альперович PC WEEK/RE (перепечатано с сайта OLAP.Ru)
Что такое OLAP сегодня, в общем-то знает каждый специалист. По крайней мере, понятия «OLAP» и «многомерные данные» устойчиво связаны в нашем сознании. Тем не менее тот факт, что эта тема вновь поднимается, надеюсь, будет одобрен большинством читателей, т. к. для того, чтобы представление о чем-либо с течением времени не устаревало, нужно периодически общаться с умными людьми или читать статьи в хорошем издании…
Хранилища данных (место OLAP в информационной структуре предприятия)
Термин «OLAP» неразрывно связан с термином «хранилище данных» (Data Warehouse).
Приведем определение, сформулированное «отцом-основателем» хранилищ данных Биллом Инмоном: «Хранилище данных — это предметно-ориентированное, привязанное ко времени и неизменяемое собрание данных для поддержки процесса принятия управляющих решений».
Данные в хранилище попадают из оперативных систем (OLTP-систем), которые предназначены для автоматизации бизнес-процессов. Кроме того, хранилище может пополняться за счет внешних источников, например статистических отчетов.
Зачем строить хранилища данных — ведь они содержат заведомо избыточную информацию, которая и так «живет» в базах или файлах оперативных систем? Ответить можно кратко: анализировать данные оперативных систем напрямую невозможно или очень затруднительно. Это объясняется различными причинами, в том числе разрозненностью данных, хранением их в форматах различных СУБД и в разных «уголках» корпоративной сети. Но даже если на предприятии все данные хранятся на центральном сервере БД (что бывает крайне редко), аналитик почти наверняка не разберется в их сложных, подчас запутанных структурах. Автор имеет достаточно печальный опыт попыток «накормить» голодных аналитиков «сырыми» данными из оперативных систем — им это оказалось «не по зубам».
Таким образом, задача хранилища — предоставить «сырье» для анализа в одном месте и в простой, понятной структуре. Ральф Кимбалл в предисловии к своей книге «The Data Warehouse Toolkit» пишет, что если по прочтении всей книги читатель поймет только одну вещь, а именно: структура хранилища должна быть простой, — автор будет считать свою задачу выполненной.
Есть и еще одна причина, оправдывающая появление отдельного хранилища — сложные аналитические запросы к оперативной информации тормозят текущую работу компании, надолго блокируя таблицы и захватывая ресурсы сервера.
На мой взгляд, под хранилищем можно понимать не обязательно гигантское скопление данных — главное, чтобы оно было удобно для анализа. Вообще говоря, для маленьких хранилищ предназначается отдельный термин — Data Marts (киоски данных), но в нашей российской практике его не часто услышишь.
OLAP — удобный инструмент анализа
Централизация и удобное структурирование — это далеко не все, что нужно аналитику. Ему ведь еще требуется инструмент для просмотра, визуализации информации. Традиционные отчеты, даже построенные на основе единого хранилища, лишены одного — гибкости. Их нельзя «покрутить», «развернуть» или «свернуть», чтобы получить желаемое представление данных. Конечно, можно вызвать программиста (если он захочет придти), и он (если не занят) сделает новый отчет достаточно быстро — скажем, в течение часа (пишу и сам не верю — так быстро в жизни не бывает; давайте дадим ему часа три). Получается, что аналитик может проверить за день не более двух идей. А ему (если он хороший аналитик) таких идей может приходить в голову по нескольку в час. И чем больше «срезов» и «разрезов» данных аналитик видит, тем больше у него идей, которые, в свою очередь, для проверки требуют все новых и новых «срезов». Вот бы ему такой инструмент, который позволил бы разворачивать и сворачивать данные просто и удобно! В качестве такого инструмента и выступает OLAP.
Хотя OLAP и не представляет собой необходимый атрибут хранилища данных, он все чаще и чаще применяется для анализа накопленных в этом хранилище сведений.
Компоненты, входящие в типичное хранилище, представлены на рис. 1.
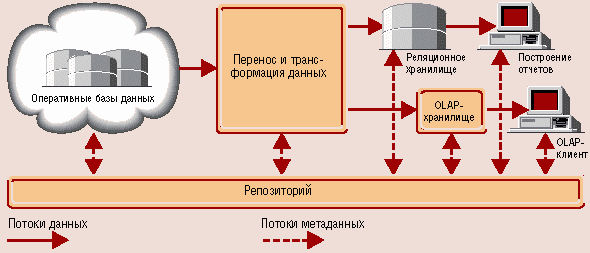
Рис. 1. Структура хранилища данных
Оперативные данные собираются из различных источников, очищаются, интегрируются и складываются в реляционное хранилище. При этом они уже доступны для анализа при помощи различных средств построения отчетов. Затем данные (полностью или частично) подготавливаются для OLAP-анализа. Они могут быть загружены в специальную БД OLAP или оставлены в реляционном хранилище. Важнейшим его элементом являются метаданные, т. е. информация о структуре, размещении и трансформации данных. Благодаря им обеспечивается эффективное взаимодействие различных компонентов хранилища.
Подытоживая, можно определить OLAP как совокупность средств многомерного анализа данных, накопленных в хранилище. Теоретически средства OLAP можно применять и непосредственно к оперативным данным или их точным копиям (чтобы не мешать оперативным пользователям). Но мы тем самым рискуем наступить на уже описанные выше грабли, т. е. начать анализировать оперативные данные, которые напрямую для анализа непригодны.
Определение и основные понятия OLAP
Для начала расшифруем: OLAP — это Online Analytical Processing, т. е. оперативный анализ данных. 12 определяющих принципов OLAP сформулировал в 1993 г. Е. Ф. Кодд — «изобретатель» реляционных БД. Позже его определение было переработано в так называемый тест FASMI, требующий, чтобы OLAP-приложение предоставляло возможности быстрого анализа разделяемой многомерной информации ().
Тест FASMI
Fast (Быстрый) — анализ должен производиться одинаково быстро по всем аспектам информации. Приемлемое время отклика — 5 с или менее.
Analysis (Анализ) — должна быть возможность осуществлять основные типы числового и статистического анализа, предопределенного разработчиком приложения или произвольно определяемого пользователем.
Shared (Разделяемой) — множество пользователей должно иметь доступ к данным, при этом необходимо контролировать доступ к конфиденциальной информации.
Multidimensional (Многомерной) — это основная, наиболее существенная характеристика OLAP.
Information (Информации) — приложение должно иметь возможность обращаться к любой нужной информации, независимо от ее объема и места хранения.
OLAP = многомерное представление = Куб
OLAP предоставляет удобные быстродействующие средства доступа, просмотра и анализа деловой информации. Пользователь получает естественную, интуитивно понятную модель данных, организуя их в виде многомерных кубов (Cubes). Осями многомерной системы координат служат основные атрибуты анализируемого бизнес-процесса. Например, для продаж это могут быть товар, регион, тип покупателя. В качестве одного из измерений используется время. На пересечениях осей — измерений (Dimensions) — находятся данные, количественно характеризующие процесс — меры (Measures). Это могут быть объемы продаж в штуках или в денежном выражении, остатки на складе, издержки и т. п. Пользователь, анализирующий информацию, может «разрезать» куб по разным направлениям, получать сводные (например, по годам) или, наоборот, детальные (по неделям) сведения и осуществлять прочие манипуляции, которые ему придут в голову в процессе анализа.
В качестве мер в трехмерном кубе, изображенном на рис. 2, использованы суммы продаж, а в качестве измерений — время, товар и магазин. Измерения представлены на определенных уровнях группировки: товары группируются по категориям, магазины — по странам, а данные о времени совершения операций — по месяцам. Чуть позже мы рассмотрим уровни группировки (иерархии) подробнее.

Рис. 2. Пример куба
«Разрезание» куба
Даже трехмерный куб сложно отобразить на экране компьютера так, чтобы были видны значения интересующих мер. Что уж говорить о кубах с количеством измерений, большим трех? Для визуализации данных, хранящихся в кубе, применяются, как правило, привычные двумерные, т. е. табличные, представления, имеющие сложные иерархические заголовки строк и столбцов.
Двумерное представление куба можно получить, «разрезав» его поперек одной или нескольких осей (измерений): мы фиксируем значения всех измерений, кроме двух, — и получаем обычную двумерную таблицу. В горизонтальной оси таблицы (заголовки столбцов) представлено одно измерение, в вертикальной (заголовки строк) — другое, а в ячейках таблицы — значения мер. При этом набор мер фактически рассматривается как одно из измерений — мы либо выбираем для показа одну меру (и тогда можем разместить в заголовках строк и столбцов два измерения), либо показываем несколько мер (и тогда одну из осей таблицы займут названия мер, а другую — значения единственного «неразрезанного» измерения).

Рис. 3. Двумерный срез куба для одной меры
На рис. 4 представлено лишь одно «неразрезанное» измерение — Store, но зато здесь отображаются значения нескольких мер — Unit Sales (продано штук), Store Sales (сумма продажи) и Store Cost (расходы магазина).

Рис. 4. Двумерный срез куба для нескольких мер
Двумерное представление куба возможно и тогда, когда «неразрезанными» остаются и более двух измерений. При этом на осях среза (строках и столбцах) будут размещены два или более измерений «разрезаемого» куба — см. рис. 5.
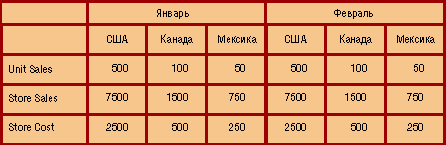
Рис. 5. Двумерный срез куба с несколькими измерениями на одной оси
Метки
Значения, «откладываемые» вдоль измерений, называются членами или метками (members). Метки используются как для «разрезания» куба, так и для ограничения (фильтрации) выбираемых данных — когда в измерении, остающемся «неразрезанным», нас интересуют не все значения, а их подмножество, например три города из нескольких десятков. Значения меток отображаются в двумерном представлении куба как заголовки строк и столбцов.
Иерархии и уровни
Метки могут объединяться в иерархии, состоящие из одного или нескольких уровней (levels). Например, метки измерения «Магазин» (Store) естественно объединяются в иерархию с уровнями:
All (Мир)
Country (Страна)
State (Штат)
City (Город)
Store (Магазин).
Архитектура OLAP-приложений
Все, что говорилось выше про OLAP, по сути, относилось к многомерному представлению данных. То, как данные хранятся, грубо говоря, не волнует ни конечного пользователя, ни разработчиков инструмента, которым клиент пользуется.
Многомерность в OLAP-приложениях может быть разделена на три уровня:
- Многомерное представление данных — средства конечного пользователя, обеспечивающие многомерную визуализацию и манипулирование данными; слой многомерного представления абстрагирован от физической структуры данных и воспринимает данные как многомерные.
- Многомерная обработка — средство (язык) формулирования многомерных запросов (традиционный реляционный язык SQL здесь оказывается непригодным) и процессор, умеющий обработать и выполнить такой запрос.
- Многомерное хранение — средства физической организации данных, обеспечивающие эффективное выполнение многомерных запросов.
Первые два уровня в обязательном порядке присутствуют во всех OLAP-средствах. Третий уровень, хотя и является широко распространенным, не обязателен, так как данные для многомерного представления могут извлекаться и из обычных реляционных структур; процессор многомерных запросов в этом случае транслирует многомерные запросы в SQL-запросы, которые выполняются реляционной СУБД.
Конкретные OLAP-продукты, как правило, представляют собой либо средство многомерного представления данных, OLAP-клиент (например, Pivot Tables в Excel 2000 фирмы Microsoft или ProClarity фирмы Knosys), либо многомерную серверную СУБД, OLAP-сервер (например, Oracle Express Server или Microsoft OLAP Services).
Слой многомерной обработки обычно бывает встроен в OLAP-клиент и/или в OLAP-сервер, но может быть выделен в чистом виде, как, например, компонент Pivot Table Service фирмы Microsoft.
Технические аспекты многомерного хранения данных
Как уже говорилось выше, средства OLAP-анализа могут извлекать данные и непосредственно из реляционных систем. Такой подход был более привлекательным в те времена, когда OLAP-серверы отсутствовали в прайс-листах ведущих производителей СУБД. Но сегодня и Oracle, и Informix, и Microsoft предлагают полноценные OLAP-серверы, и даже те IT-менеджеры, которые не любят разводить в своих сетях «зоопарк» из ПО разных производителей, могут купить (точнее, обратиться с соответствующей просьбой к руководству компании) OLAP-сервер той же марки, что и основной сервер баз данных.
OLAP-серверы, или серверы многомерных БД, могут хранить свои многомерные данные по-разному. Прежде чем рассмотреть эти способы, нам нужно поговорить о таком важном аспекте, как хранение агрегатов. Дело в том, что в любом хранилище данных — и в обычном, и в многомерном — наряду с детальными данными, извлекаемыми из оперативных систем, хранятся и суммарные показатели (агрегированные показатели, агрегаты), такие, как суммы объемов продаж по месяцам, по категориям товаров и т. п. Агрегаты хранятся в явном виде с единственной целью — ускорить выполнение запросов. Ведь, с одной стороны, в хранилище накапливается, как правило, очень большой объем данных, а с другой — аналитиков в большинстве случаев интересуют не детальные, а обобщенные показатели. И если каждый раз для вычисления суммы продаж за год пришлось бы суммировать миллионы индивидуальных продаж, скорость, скорее всего, была бы неприемлемой. Поэтому при загрузке данных в многомерную БД вычисляются и сохраняются все суммарные показатели или их часть.
Но, как известно, за все надо платить. И за скорость обработки запросов к суммарным данным приходится платить увеличением объемов данных и времени на их загрузку. Причем увеличение объема может стать буквально катастрофическим — в одном из опубликованных стандартных тестов полный подсчет агрегатов для 10 Мб исходных данных потребовал 2,4 Гб, т. е. данные выросли в 240 раз! Степень «разбухания» данных при вычислении агрегатов зависит от количества измерений куба и структуры этих измерений, т. е. соотношения количества «отцов» и «детей» на разных уровнях измерения. Для решения проблемы хранения агрегатов применяются подчас сложные схемы, позволяющие при вычислении далеко не всех возможных агрегатов достигать значительного повышения производительности выполнения запросов.
Теперь о различных вариантах хранения информации. Как детальные данные, так и агрегаты могут храниться либо в реляционных, либо в многомерных структурах. Многомерное хранение позволяет обращаться с данными как с многомерным массивом, благодаря чему обеспечиваются одинаково быстрые вычисления суммарных показателей и различные многомерные преобразования по любому из измерений. Некоторое время назад OLAP-продукты поддерживали либо реляционное, либо многомерное хранение. Сегодня, как правило, один и тот же продукт обеспечивает оба этих вида хранения, а также третий вид — смешанный. Применяются следующие термины:
- MOLAP (Multidimensional OLAP) — и детальные данные, и агрегаты хранятся в многомерной БД. В этом случае получается наибольшая избыточность, так как многомерные данные полностью содержат реляционные.
- ROLAP (Relational OLAP) — детальные данные остаются там, где они «жили» изначально — в реляционной БД; агрегаты хранятся в той же БД в специально созданных служебных таблицах.
- HOLAP (Hybrid OLAP) — детальные данные остаются на месте (в реляционной БД), а агрегаты хранятся в многомерной БД.
Каждый из этих способов имеет свои преимущества и недостатки и должен применяться в зависимости от условий — объема данных, мощности реляционной СУБД и т. д.
При хранении данных в многомерных структурах возникает потенциальная проблема «разбухания» за счет хранения пустых значений. Ведь если в многомерном массиве зарезервировано место под все возможные комбинации меток измерений, а реально заполнена лишь малая часть (например, ряд продуктов продается только в небольшом числе регионов), то бо/льшая часть куба будет пустовать, хотя место будет занято. Современные OLAP-продукты умеют справляться с этой проблемой.
Продолжение следует. В дальнейшем мы поговорим о конкретных OLAP-продуктах, выпускаемых ведущими производителями.
С автором статьи можно связаться по адресу: alperovich@digdes.com
Версия для печати
Кубы данных OLAP (Online Analytical Processing — оперативный анализ данных) позволяют эффективно извлекать и анализировать многомерные данные. В отличие от других типов баз данных, базы данных OLAP разработаны специально для аналитической обработки и быстрого извлечения из них всевозможных наборов данных. На самом деле существует несколько ключевых различий между стандартными реляционными базами данных, такими как Access или SQL Server, и базами данных OLAP.
Рис. 1. Для подключения куба OLAP к книге Excel воспользуйтесь командой Из служб аналитики
Скачать заметку в формате Word или pdf
В реляционных базах данных информация представляется в виде записей, которые добавляются, удаляются и обновляются последовательно. В базах данных OLAP хранится только моментальный снимок данных. В базе данных OLAP информация заархивирована в виде единого блока данных и предназначается только для вывода по запросу. Хотя в базу данных OLAP и можно добавлять новую информацию, существующие данные редко редактируются и тем более удаляются.
Реляционные базы данных и базы данных OLAP различаются структурно. Реляционные базы данных обычно состоят из набора таблиц, которые связаны между собой. В отдельных случаях реляционная база данных содержит так много таблиц, что очень сложно определить, как же они все-таки связаны. В базах данных OLAP связь между отдельными блоками данных определяется заранее и сохраняется в структуре, известной под названием кубы OLAP. В кубах данных хранятся полные сведения об иерархической структуре и связях базы данных, которые значительно упрощают навигацию по ней. К тому же создавать отчеты намного проще, если заранее известно, где располагаются извлекаемые данные и какие еще данные с ними связаны.
Основная же разница между реляционными базами данных и базами данных OLAP заключается в способе хранения информации. Данные в кубе OLAP редко представлены в общем виде. Кубы данных OLAP обычно содержат информацию, представленную в заранее разработанном формате. Таким образом, операции группировки, фильтрации, сортировки и объединения данных в кубах выполняются перед заполнением их информацией. Это делает извлечение и вывод запрашиваемых данных максимально упрощенной процедурой. В отличие от реляционных баз данных, нет необходимости в упорядочении информации должным образом перед выводом ее на экран.
Базы данных OLAP обычно создаются и поддерживаются администраторами IT-отдела. Если в вашей организации нет структуры, которая отвечает за управление базами данных OLAP, то можете обратиться к администратору реляционной базы данных с просьбой реализовать в корпоративной сети хотя бы отдельные OLAP-решения.
Подключение к кубу данных OLAP
Чтобы получить доступ к базе данных OLAP, сначала нужно установить подключение к кубу OLAP. Начните с перехода на вкладку ленты Данные. Щелкните на кнопке Из других источников и выберите в раскрывающемся меню команду Из служб аналитики (рис. 1).
При выборе указанной команды на экране появится диалоговое окно мастера подключения к данным (рис. 2). Основная его задача — это помочь вам установить соединение с сервером, который будет использован программой Excel при управлении данными.
1. Сначала нужно предоставить Excel регистрационную информацию. Введите в полях диалогового окна имя сервера, регистрационное имя и пароль доступа к данным, как показано на рис. 2. Щелкните на кнопке Далее. Если вы подключаетесь с помощью учетной записи Windows, то установите переключатель Использовать проверку подлинности Windows.
{kind=link}
Рис. 2. Введите регистрационные данные
2. Выберите в раскрывающемся списке базу данных, с которой будете работать (рис. 3). В текущем примере используется база данных Analysis Services Tutorial. После выбора этой базы данных в расположенном ниже списке предлагается импортировать все доступные в ней кубы OLAP. Выберите необходимый куб данных и щелкните на кнопке Далее.
Рис. 3. Выберите рабочую базу данных и куб OLAP, который планируете применять для анализа данных
3. В следующем диалоговом окне мастера, показанном на рис. 4, вам требуется ввести описательную информацию о создаваемом подключении. Все поля диалогового окна, показанного на рис. 4, не обязательны для заполнения. Вы всегда можете проигнорировать текущее диалоговое окно, не заполняя его, и это никак не скажется на подключении.
{kind=link}
Рис. 4. Измените описательную информацию о соединении
4. Щелкните на кнопке Готово, чтобы завершить создание подключения. На экране появится диалоговое окно Импорт данных (рис. 5). Установите переключатель Отчет сводной таблицы и щелкните на кнопке ОК, чтобы начать создание сводной таблицы.
Рис. 5. Завершив настройку подключения, можете приниматься за создание сводной таблицы
Структура куба OLAP
В процессе создания сводной таблицы на основе базы данных OLAP вы заметите, что окно области задач Поля сводной таблицы будет отличаться от такового для обычной сводной таблицы. Причина кроется в упорядочении сводной таблицы так, чтобы максимально близко отобразить структуру куба OLAP, присоединенного к ней. Чтобы максимально быстро перемещаться по кубу OLAP, необходимо детально ознакомиться с его компонентами и способами их взаимодействия. На рис. 6 показана базовая структура типичного куба OLAP.
{kind=link}
Рис. 6. Базовая структура куба данных OLAP
Как видите, основные компоненты куба OLAP – это размерности, иерархии, уровни, члены и меры:
- Размерности. Основная характеристика анализируемых элементов данных. К наиболее общим примерам размерностей относятся Products (Товары), Customer (Покупатель) и Employee (Сотрудник). На рис. 6 показана структура размерности Products.
- Иерархии. Заранее определенная агрегация уровней в указанной размерности. Иерархия позволяет создавать сводные данные и анализировать их на различных уровнях структуры, не вникая во взаимосвязи, существующие между этими уровнями. В примере, показанном на рис. 6, размерность Products имеет три уровня, которые агрегированы в единую иерархию Product Categories (Категории товаров).
- Уровни. Уровни представляют собой категории, которые агрегируются в общую иерархию. Считайте уровни полями данных, которые можно запрашивать и анализировать отдельно друг от друга. На рис. 6 представлены всего три уровня: Category (Категория), SubCategory (Подкатегория) и Product Name (Название товара).
- Члены. Отдельный элемент данных в пределах размерности. Доступ к членам обычно реализуется через OLАР-структуру размерностей, иерархий и уровней. В примере на рис. 6 члены заданы для уровня Product Name. Другие уровни имеют свои члены, которые в структуре не показаны.
- Меры — это реальные данные в кубах OLAP. Меры сохраняются в собственных размерностях, которые называются размерностями мер. С помощью произвольной комбинации размерностей, иерархий, уровней и членов можно запрашивать меры. Подобная процедура называется «нарезкой» мер.
Теперь, когда вы ознакомились со структурой кубов OLAP, давайте по-новому взглянем на список полей сводной таблицы. Организация доступных полей становится понятной и не вызывает нареканий. На рис. 7 показано, как в списке полей представляются элементы сводной таблицы OLAP.
{kind=link}
Рис. 7. Список полей сводной таблицы OLAP
В списке полей сводной таблицы OLAP меры выводятся первыми и обозначаются значком суммирования (сигма). Это единственные элементы данных, которые могут находиться в области ЗНАЧЕНИЯ. После них в списке указываются размерности, обозначенные значком с изображением таблицы. В нашем примере используется размерность Customer. В эту размерность вложен ряд иерархий. После развертывания иерархии можно ознакомиться с отдельными уровнями данных. Для просмотра структуры данных куба OLAP достаточно перемещаться по списку полей сводной таблицы.
Ограничения, накладываемые на сводные таблицы OLAP
Работая со сводными таблицами OLAP, следует помнить, что взаимодействие с источником данных сводной таблицы осуществляется в среде Analysis Services OLAP. Это означает, что каждый поведенческий аспект куба данных, начиная с размерностей и заканчивая мерами, которые включены в куб, также контролируется аналитическими службами OLAP. В свою очередь, это приводит к ограничениям, накладываемым на операции, которые можно выполнять в сводных таблицах OLAP:
- нельзя поместить в область ЗНАЧЕНИЯ сводной таблицы поля, отличные от мер;
- невозможно изменить функцию, применяемую для подведения итогов;
- нельзя создать вычисляемое поле или вычисляемый элемент;
- любые изменения в именах полей отменяются сразу же после удаления этого поля из сводной таблицы;
- не допускается изменение параметров поля страницы;
- недоступна команда Показать страницы;
- отключен параметр Показывать подписи элементов при отсутствии полей в области значений;
- отключен параметр Промежуточные суммы по отобранным фильтром элементам страницы;
- недоступен параметр Фоновый запрос;
- после двойного щелчка в поле ЗНАЧЕНИЯ возвращаются только первые 1000 записей из кеша сводной таблицы;
- недоступен флажок Оптимизировать память.
Создание автономных кубов данных
В стандартной сводной таблице исходные данные хранятся на локальном жестком диске. Таким образом, вы всегда можете управлять ими, а также изменять структуру, даже не имея доступа к сети. Но это ни в коей мере не касается сводных таблиц OLAP. В сводных таблицах OLAP кеш не находится на локальном жестком диске. Поэтому сразу же после отключения от локальной сети ваша сводная таблица OLAP утратит работоспособность. Вы не сможете переместить ни одного поля в такой таблице.
Если все же нужно анализировать OLAP-данные при отсутствии подключения к сети, создайте автономный куб данных. Это отдельный файл, который представляет собой кеш сводной таблицы. В этом файле хранятся OLAP-данные, просматриваемые после отключения от локальной сети. Чтобы создать автономный куб данных, сначала создайте сводную таблицу OLAP. Поместите курсор в сводную таблицу и щелкните на кнопке Средства OLAP контекстной вкладки Анализ, входящей в набор контекстных вкладок Работа со сводными таблицами. Выберите команду Автономный режим OLAP (рис. 8).
Рис. 8. Создание автономного куба данных
На экране появится диалоговое окно Настройка автономной работы OLAP (рис. 9). Щелкните на кнопке Создать автономный файл данных. На экране появится первое окно мастера создания файла куба данных. Щелкните на кнопке Далее, чтобы продолжить процедуру.
Рис. 9. Начальное окно мастера создания автономного куба данных
На втором шаге (рис. 10), укажите размерности и уровни, которые будут включаться в куб данных. В диалоговом окне необходимо выбрать данные, импортируемые из базы данных OLAP. Нужно выделить только те размерности, которые понадобятся после отключения компьютера от локальной сети. Чем больше размерностей укажете, тем больший размер будет иметь автономный куб данных.
Рис. 10. Укажите размерность и уровни, включаемые в автономный куб данных
Щелкните на кнопке Далее для перехода к третьему шагу (рис. 11). В этом окне нужно выбрать члены или элементы данных, которые не будут включаться в куб. Если флажок не установлен, указанный элемент не будет импортироваться и занимать лишнее место на локальном жестком диске.
Рис. 11. He устанавливайте флажки для элементов данных, которые не должны включаться в автономный куб данных
Укажите расположение и имя куба данных (рис. 12). Файлы кубов данных имеют расширение .cub.
Рис. 12. Укажите имя и расположение файла куба данных
Спустя некоторое время Excel сохранит автономный куб данных в указанной папке. Чтобы протестировать его, дважды щелкните на файле, что приведет к автоматической генерации рабочей книги Excel, которая содержит сводную таблицу, связанную с выбранным кубом данных. После создания вы можете распространить автономный куб данных среди всех заинтересованных пользователей, которые работают в режиме отключенной локальной сети.
После подключения к локальной сети можно открыть файл автономного куба данных и обновить его, а также соответствующую таблицу данных. Учтите, что хотя автономный куб данных применяется при отсутствии доступа к сети, он в обязательном порядке обновляется после восстановления подключения к сети. Попытка обновления автономного куба данных после разрыва соединения с сетью приведет к сбою.
Применение функций куба данных в сводных таблицах
Функции куба данных, которые применяются в базах данных OLAP, могут запускаться и из сводной таблицы. В устаревших версиях Excel вы получали доступ к функциям кубов данных только после установки надстройки Пакет анализа. В Excel 2013 данные функции встроены в программу, а потому доступны для применения. Чтобы в полной мере ознакомиться с их возможностями, рассмотрим конкретный пример.
Один из самых простых способов изучения функций куба данных заключается в преобразовании сводной таблицы OLAP в формулы куба данных. Эта процедура очень простая и позволяет быстро получить формулы куба данных, не создавая их «с нуля». Ключевой принцип — заменить все ячейки в сводной таблице формулами, которые связаны с базой данных OLAP. На рис. 13 показана сводная таблица, связанная с базой данных OLAP.
{kind=link}
Рис. 13. Обычная сводная таблица OLAP
Поместите курсор в любом месте сводной таблицы, щелкните на кнопке Средства OLAP контекстной вкладки ленты Анализ и выберите команду Преобразовать в формулы (рис. 14).
Рис. 14. Преобразование сводной таблицы в формулы куба данных
Если ваша сводная таблица содержит поле фильтра отчета, то на экране появится диалоговое окно, показанное на рис. 15. В этом окне следует указать, нужно ли преобразовывать в формулы раскрывающиеся списки фильтров данных. При положительном ответе раскрывающиеся списки будут удалены, а вместо них будут отображены статические формулы. Если же вы в дальнейшем планируете использовать раскрывающиеся списки для изменения содержимого сводной таблицы, то сбросьте единственный флажок диалогового окна. Если вы работаете над сводной таблицей в режиме совместимости, то фильтры данных будут преобразовываться в формулы автоматически, без предварительного предупреждения.
Рис. 15. В Excel можно преобразовать фильтры данных сводной таблицы в статические формулы
Спустя несколько секунд вместо сводной таблицы отобразятся формулы, которые выполняются в кубах данных и обеспечивают вывод в окне Excel необходимой информации. Обратите внимание на то, что при этом удаляются ранее примененные стили (рис. 16).
Рис. 16. Взгляните на строку формул: в ячейках содержатся формулы куба данных
Учитывая то, что просматриваемые вами значения теперь не являются частью объекта сводной таблицы, можно добавлять столбцы, строки и вычисляемые элементы, комбинировать их с другими внешними источниками, а также изменять отчет самыми разными способами, в том числе и перетаскивая формулы.
Добавление вычислений в сводные таблицы OLAP
В предыдущих версиях Excel в сводных таблицах OLAP не допускались пользовательские вычисления. Это означает, что в сводные таблицы OLAP было невозможно добавить дополнительный уровень анализа подобно тому, как это делается в обычных сводных таблицах, допускающих добавление вычисляемых полей и элементов (подробнее см. Вычисляемые поля и вычисляемые элементы в Excel 2013; прежде чем продолжить чтение, убедитесь, что вы хорошо знакомы с этим материалом).
В Excel 2013 появились новые инструменты OLAP — вычисляемые меры и вычисляемые элементы многомерных выражений. Теперь вы не ограничены использованием мер и элементов в кубе OLAP, предоставленных администратором базы данных. Вы получаете дополнительные возможности анализа путем создания пользовательских вычислений.
Знакомство с MDX. При использовании сводной таблицы вместе с кубом OLAP вы отсылаете базе данных запросы MDX (Multidimensional Expressions — многомерные выражения). MDX — это язык запросов, применяемый для получения данных из многомерных источников (например, из кубов OLAP). В случае изменения или обновления сводной таблицы OLAP соответствующие запросы MDX передаются базе данных OLAP. Результаты выполнения запроса возвращаются обратно в Excel и отображаются в области сводной таблицы. Таким образом обеспечивается возможность работы с данными OLAP без локальной копии кеша сводных таблиц.
При создании вычисляемых мер и элементов многомерных выражений применяется синтаксис языка MDX. С помощью этого синтаксиса сводная таблица обеспечивает взаимодействие вычислений с серверной частью базы данных OLAP. Примеры, рассматриваемые в книге, основаны на базовых конструкциях MDX, демонстрирующих новые функции Excel 2013. Если необходимо создавать сложные вычисляемые меры и элементы многомерных выражений, придется потратить время на более глубокое изучение возможностей MDX.
Создание вычисляемых мер. Вычисляемая мера представляет собой OLAP-версию вычисляемого поля. Идея заключается в создании нового поля данных на основе некоторых математических операций, выполняемых по отношению к существующим полям OLAP. В примере, показанном на рис. 17, используется сводная таблица OLAP, которая включает перечень и количество товаров, а также доход от продажи каждого из них. Нужно добавить новую меру, которая будет вычислять среднюю цену за единицу товара.
Рис. 17. В сводную таблицу OLAP будет добавлена мера, вычисляющая среднюю цену единицы товара
Поместите курсор в любом месте сводной таблицы и выберите контекстную вкладку Анализ из набора контекстных вкладок Работа со сводными таблицами. В раскрывающемся меню Средства OLAP выберите пункт Вычисляемая мера многомерного выражения (рис. 18).
Рис. 18. Выберите пункт меню Вычисляемая мера многомерного выражения
На экране появится диалоговое окно Создание вычисляемой меры (рис. 19).
Рис. 19. В данном окне создается вычисляемая мера
Выполните следующие действия:
1. Присвойте вычисляемой мере имя.
2. Выберите группу мер, в которой будет находиться новая вычисляемая мера. Если этого не сделать, Excel автоматически поместит новую меру в первую доступную группу мер.
3. В поле Многомерное выражение (MDX) введите код, задающий новую меру. Чтобы ускорить процесс ввода, воспользуйтесь находящимся слева списком для выбора существующих мер, которые будут использованы в вычислениях. Дважды щелкните на нужной мере, чтобы добавить ее в поле Многомерное выражение. Для вычисления средней цены продажи единицы товара используется следующее многомерное выражение:
IIF (
. = 0
,NULL
,./
)
4. Кликните ОК.
Обратите внимание на кнопку Проверить MDX, которая находится в правой нижней части окна. Щелкните на этой кнопке, чтобы проверить корректность синтаксиса многомерного выражения. Если синтаксис содержит ошибки, отобразится соответствующее сообщение.
После завершения создания новой вычисляемой меры перейдите в список Поля сводной таблицы и выберите ее (рис. 20).
Рис. 20. Добавьте в сводную таблицу OLAP новую вычисляемую меру
Только что созданная вычисляемая мера добавила еще один уровень анализа в сводную таблицу (рис. 21).
Рис. 21. В сводной таблице появилась новая вычисляемая мера
Область действия вычисляемой меры распространяется только на текущую книгу. Другими словами, вычисляемые меры не создаются непосредственно в кубе OLAP сервера. Это означает, что никто не сможет получить доступ к вычисляемой мере, если только вы не откроете общий доступ к рабочей книге либо не опубликуете ее в Интернете.
Создание вычисляемых элементов многомерных выражений. Вычисляемый элемент многомерного выражения представляет собой OLAP-версию обычного вычисляемого элемента. Идея заключается в создании нового элемента данных, основанного на некоторых математических операциях, выполняемых по отношению к существующим элементам OLAP. В примере, показанном на рис. 22, используется сводная таблица OLAP, включающая сведения о продажах за 2005–2008 годы (с поквартальной разбивкой). Предположим, нужно выполнить агрегирование данных, относящихся к первому и второму кварталам, создав новый элемент First Half of Year (Первая половина года). Также объединим данные, относящиеся к третьему и четвертому кварталам, сформировав новый элемент Second Half of Year (Вторая половина года).
Рис. 22. Мы собираемся добавить новые вычисляемые элементы многомерных выражений, First Half of Year и Second Half of Year
Поместите курсор в любом месте сводной таблицы и выберите контекстную вкладку Анализ из набора контекстных вкладок Работа со сводными таблицами. В раскрывающемся меню Средства OLAP выберите пункт Вычисляемый элемент многомерного выражения (рис. 23).
Рис. 23. Создание нового вычисляемого элемента многомерного выражения
На экране появится диалоговое окно Создание вычисляемого элемента (рис. 24).
Рис. 24. Окно Создание вычисляемого элемента
Выполните следующие действия:
1. Присвойте вычисляемой мере имя.
2. Выберите родительскую иерархию, для которой создаются новые вычисляемые элементы. Настройке Родительский элемент присвойте значение Все. Благодаря этой настройке Excel получает доступ ко всем элементам родительской иерархии при вычислении выражения.
3. В окне Многомерное выражение введите синтаксис многомерного выражения. Чтобы немного сэкономить время, воспользуйтесь отображенным слева списком для выбора существующих элементов, используемых в многомерном выражении. Дважды щелкните на выбранном элементе, и Excel добавит его в окно Многомерное выражение. В примере, показанном на рис. 24, вычисляется сумма первого и второго кварталов:
..&& +
.. && +
.. && + …
4. Щелкните ОК. Excel отобразит только что созданный вычисляемый элемент многомерного выражения в сводной таблице. Как показано на рис. 25, новый вычисляемый элемент отображается вместе с другими вычисляемыми элементами сводной таблицы.
Рис. 25. Excel добавляет новый вычисляемый элемент в поле сводной таблицы
На рис. 26 иллюстрируется аналогичный процесс, применяемый для создания вычисляемого элемента Second Half of Year.
Рис. 26. Повторите описанный ранее процесс для создания других вычисляемых элементов многомерного выражения
Обратите внимание: Excel даже не пытается удалить исходные элементы многомерного выражения (рис. 27). В сводной таблице по-прежнему отображаются записи, соответствующие 2005–2008 годам с поквартальной разбивкой. В рассматриваемом случае это не страшно, но в большинстве сценариев следует скрывать «лишние» элементы во избежание появления конфликтов.
Рис. 27. Excel отображает созданный вычисляемый элемент многомерного выражения наравне с исходными элементами. Но все же лучше удалять исходные элементы во избежание конфликтов
Помните: вычисляемые элементы находятся только в текущей рабочей книге. Другими словами, вычисляемые меры не создаются непосредственно в кубе OLAP сервера. Это означает, что никто не сможет получить доступ к вычисляемой мере либо вычисляемому элементу, если только вы не откроете общий доступ к рабочей книге либо не опубликуете ее в Интернете.
Следует отметить, что в случае изменения родительской иерархии или родительского элемента в кубе OLAP вычисляемый элемент многомерного выражения перестает выполнять свои функции. Потребуется повторно создать этот элемент.
Управление вычислениями OLAP. В Excel поддерживается интерфейс, позволяющий управлять вычисляемыми мерами и элементами многомерных выражений в сводных таблицах OLAP. Поместите курсор в любом месте сводной таблицы и выберите контекстную вкладку Анализ из набора контекстных вкладок Работа со сводными таблицами. В раскрывающемся меню Средства OLAP выберите пункт Управление вычислениями. В окне Управления вычислениями доступны три кнопки (рис. 28):
- Создать. Создание новой вычисляемой меры или вычисляемого элемента многомерного выражения.
- Изменить. Изменение выбранного вычисления.
- Удалить. Удаление выделенного вычисления.
Рис. 28. Диалоговое окне Управление вычислениями
Выполнение анализа «что, если» по данным OLAP. В Excel 2013 можно выполнять анализ «что, если» для данных, находящихся в сводных таблицах OLAP. Благодаря этой новой возможности можно изменять значения в сводной таблице и повторно вычислять меры и элементы на основании внесенных изменений. Можно также распространить изменения обратно на куб OLAP. Чтобы воспользоваться возможностями анализа «что, если», создайте сводную таблицу OLAP и выберите контекстную вкладку Анализ, находящуюся в наборе контекстных вкладок Работа со сводными таблицами. В раскрывающемся меню Средства OLAP выберите команду Анализ «что, если» –> Включить анализ «что, если» (рис. 29).
Рис. 29. После включения анализа «что, если» можно изменять данные в сводной таблице
Начиная с этого момента можно изменять значения сводной таблицы. Чтобы изменить выбранное значение в сводной таблице, щелкните на нем правой кнопкой мыши и в контекстном меню выберите пункт Учесть изменение при расчете сводной таблицы (рис. 30). Excel повторно выполнит все вычисления в сводной таблице с учетом внесенных правок, включая вычисляемые меры и вычисляемые элементы многомерных выражений.
Рис. 30. Выберите пункт Учесть изменение при расчете сводной таблицы, чтобы внести изменения в сводную таблицу
По умолчанию правки, внесенные в сводную таблицу в режиме анализа «что, если», являются локальными. Если же вы хотите распространить изменения на сервер OLAP, выберите команду для публикации изменений. Выберите контекстную вкладку Анализ, находящуюся в наборе контекстных вкладок Работа со сводными таблицами. В раскрывающемся меню Средства OLAP выберите пункты Анализ «что, если» – > Опубликовать изменения (рис. 31). В результате выполнения этой команды включится «обратная запись» на сервере OLAP, что означает возможность распространения изменений на исходный куб OLAP. (Чтобы распространять изменения на сервер OLAP, нужно обладать соответствующими разрешениями на доступ к серверу. Обратитесь к администратору баз данных, который поможет вам получить разрешения на доступ в режиме записи к базе данных OLAP.)
Рис. 31. В Excel 2013 можно распространить изменения обратно на исходный куб OLAP
Алексей Федоров,
Наталия Елманова, преподаватель УКЦ «Interface Ltd»,
КомпьютерПресс 8’2001
Создание коллективных измерений
Создание измерения типа «дата/время»
Создание регулярного измерения
Создание измерения с несбалансированной иерархией
Создание измерения типа «родитель-потомок»
Создание OLAP-кубов
Создание описания куба
Создание вычисляемых выражений
Создание многомерного хранилища данных
Заключение
В предыдущей статье данного цикла «Создание и заполнение хранилищ данных с помощью Data Transformation Services» мы обсудили вопросы заполнения хранилищ данных и синхронизации их с содержимым оперативной базы данных. На этот раз мы рассмотрим, как на основании хранилищ данных можно создавать многомерные базы данных и OLAP-кубы с помощью Microsoft Analysis Services — аналитических сервисов, с архитектурой которых мы уже знакомы («Архитектура Microsoft Analysis Services»).
Создание многомерных баз данных и описание источников данных
Рассмотрим создание многомерного OLAP-куба на основании хранилища данных Northwind_Mart, которое мы создали и заполнили в предыдущей статье. Напомним, что это хранилище содержит таблицу фактов Sales_Fact и таблицы измерений Employee_Dim, Customer_Dim, Product_Dim, Time_Dim, Shipper_Dim. Отметим, что в процессе создания куба нам придется несколько модифицировать наше хранилище данных, с тем чтобы оно позволяло производить некоторые специальные виды анализа данных.
Для выполнения этого примера следует установить аналитические службы Microsoft SQL Server (напоминаем, что они входят в комплект поставки Microsoft SQL Server Enterprise Edition, Standard Edition, Developer Edition и Personal Edition) и запустить утилиту Analysis Manager, с помощью которой обычно и создаются многомерные базы данных.
Прежде всего следует зарегистрировать в Analysis Manager OLAP-сервер (он может находиться как на локальном компьютере, так и на другом компьютере в рамках локальной сети), выбрав пункт Register Server… из контекстного меню элемента Analysis Servers в левой части главного окна Analysis Manager. Затем нужно соединиться с OLAP-сервером, выбрав пункт Connect контекстного меню соответствующего элемента.
Поскольку OLAP-кубы хранятся в многомерных базах данных, создадим таковую, выбрав пункт New Database… из контекстного меню элемента, соответствующего OLAP-серверу, и введем имя базы данных и ее описание.
Прежде чем создавать OLAP-кубы, необходимо описать источники исходных данных для них. В нашем примере таким источником является созданное ранее хранилище Northwind_Mart. Для описания источника данных выберем из контекстного меню элемента Data Sources пункт New Data Source… и заполним поля стандартной диалоговой панели Data Link Properties: в качестве провайдера данных укажем OLE DB Provider for SQL Server и выберем базу данных Northwind_Mart (рис. 1).
Рис. 1. Создание источника данных
Теперь можно приступать к созданию измерений и кубов.
Как мы уже знаем из предыдущих статей данного цикла, у OLAP-куба должно быть как минимум одно измерение. В Microsoft SQL Server Analysis Services измерения делятся на коллективные (shared dimensions) и частные (private dimensions).
Коллективные измерения — это измерения, которые могут быть использованы одновременно в нескольких кубах. Их применение удобно в том случае, когда измерение основано на стандартных данных, применимых при анализе различных предметных областей. Типичным примером создания таких измерений может быть, например, список сотрудников компании. Коллективные измерения принадлежат самой многомерной базе данных и не зависят от того, какие кубы имеются в многомерной базе данных и есть ли они там вообще.
Частные измерения принадлежат конкретному кубу и создаются вместе с ним. Они применяются в том случае, когда данное измерение имеет смысл только в одной конкретной предметной области.
Создать как коллективное, так и частное измерение можно двумя способами: с помощью соответствующего мастера и с помощью редактора измерений.
В качестве примера создадим коллективное измерение, основанное на таблице хранилища данных Time_Dim, воспользовавшись мастером создания измерений (Dimension wizard). Запустить его можно с помощью команды New Dimension | Wizard из контекстного меню элемента Shared Dimensions. Затем необходимо ответить на вопросы мастера создания измерений. В первую очередь следует выбрать, на основании чего мы создаем измерение. Поскольку исходное хранилище данных основано на схеме «звезда», выберем в мастере создания измерений опцию Star Schema: a single dimension table, а затем — имя таблицы, служащей источником данных для создаваемого измерения (в нашем примере — Time_Dim, рис. 2):
Рис. 2. Выбор таблицы для создания измерения
Иерархия данных в измерениях, основанных на данных типа «дата/время», подчиняется определенным стандартным правилам — ведь время измеряется в годах, месяцах, днях, часах, минутах независимо от того, какую предметную область мы анализируем. Поэтому измерения в OLAP-средствах обычно делятся на стандартные (не имеющие отношения ко времени) и временные. Поскольку наше измерение относится к последним, в диалоговой панели Select the dimension type выберем опцию Time Dimension и в качестве колонки, в которой содержатся данные типа «дата/время», укажем поле TheDate.
Теперь нам необходимо выбрать уровни иерархии измерений (например, решить, интересна ли нам информация о часах и минутах, нужны ли нам номера недель года и т.д.), а также определить, когда начинается год с точки зрения данного измерения. Это довольно важная возможность — ведь во многих странах начало финансового года не совпадает с началом года календарного. В нашем случае выберем уровни Year, Quarter, Month, Day и согласимся с тем, что год начинается 1 января (рис. 3).
Рис. 3. Создание измерения типа «дата/время»
Далее нам предстоит выбрать, является ли измерение изменяющимся (changing dimension). В изменяющихся измерениях (новинка в SQL Server 2000) можно перемещать члены измерений между уровнями без перерасчета данных измерения, что во многих случаях бывает удобно. Однако измерения типа Time, как правило, не делают изменяющимися — обычно никто не перемещает месяцы из одного года в другой. Поэтому в данном случае мы не будем выбирать эту опцию.
В заключительной диалоговой панели мы должны ввести имя будущего измерения и, если есть необходимость, создать иерархию в измерении и задать ее имя. Дело в том, что при необходимости можно создать еще одно измерение, основанное на тех же данных, с тем же именем, но с другой иерархией, например Year, Week, Day; в этом случае мы имеем разное представление одних и тех же данных. Присвоим созданной иерархии имя YQMD (рис. 4).
Рис. 4. Создание источника данных
Создание измерения заканчивается запуском редактора измерений — Dimension Editor. В нем при необходимости можно внести изменения в структуру измерения, например добавив дополнительные уровни или свойства членов измерения. Так, если мы планируем анализировать зависимость продаж от дня недели или сравнивать продажи в выходные, праздничные и будние дни, можно перенести в раздел Member Properties уровня Day поля Day of Week, Holiday и Weekend исходной таблицы Time_Dim (рис. 5).
Рис. 5. Dimension Editor
Теперь можно сохранить созданное измерение, выбрав пункт меню File | Save, и закрыть редактор измерений.
Повторим все указанные действия, выбрав при этом другую иерархию — Year, Week, Day, и назовем вновь созданное измерение Time.YWD.
Создание регулярного измерения
Следующее коллективное измерение создадим с помощью редактора измерений. Запустить его можно с помощью команды New Dimension | Editor из контекстного меню элемента Shared Dimensions. Далее в диалоговой панели Select the dimension table выберем таблицу Product_Dim. В редакторе измерений создадим два уровня иерархии этого измерения — CategoryName и ProductName — и перенесем мышью соответствующие имена полей в левую часть редактора измерений. В качестве свойств членов измерения уровня ProductName выберем поля SupplierName и ListUnitPrice. Поскольку переносить продукты из одной категории в другую представляется более разумным, чем переносить месяцы из одного года в другой, сделаем это измерение изменяющимся — соответствующее свойство доступно на вкладке Advanced панели Properties в левой нижней части редактора измерений. Сохраним созданное измерение под именем Product (рис. 6).
Рис. 6. Создание регулярного измерения в Dimension Editor
Следующее измерение будет содержать географические сведения. Такие измерения являются типичными кандидатами для создания так называемых неровных (ragged) иерархий — частного случая несбалансированных (unbalanced) иерархий. Как известно, административно-территориальное деление в разных странах осуществляется по разным правилам: в некоторых странах есть регионы, штаты, административные округа, а в некоторых достаточно указать населенный пункт, и в этом случае сведения о штате или регионе могут отсутствовать.
Чтобы создать измерение с несбалансированной иерархией, добавим в хранилище данных представление, которое будет содержать исходные данные для создания этого измерения:
CREATE VIEW dbo.CustomerView_Dim AS SELECT CustomerKey, CustomerID, CompanyName, ContactName, ContactTitle, Address, City, Region, REPLACE(Region, ‘Other’, Country) AS Region1, PostalCode, Country, Phone, Fax FROM dbo.Customer_Dim
Это представление содержит данные из таблицы Customer_Dim, а также вычисляемое поле Region1, содержащее название страны вместо строки «Other» в тех случаях, когда сведения о клиенте не содержат данных о регионе или штате. Это поле нам потребуется в дальнейшем для создания несбалансированной иерархии.
Теперь создадим измерение, основанное на вновь созданном представлении CustomerView_Dim хранилища данных. Последовательность действий в этом случае сходна с предыдущим примером. В качестве уровней иерархии этого измерения мы выберем поля Country, Region1, City, CompanyName. Добавим в раздел Member Properties уровня Company Name поля Contact Name и Contact Title.
Несбалансированные иерархии обычно базируются на сокрытии членов измерения, содержащих избыточные сведения. В данном случае таковым является уровень Region1. Выберем его в редакторе измерений и на странице Advanced раздела Properties установим свойство Hide Member If равным Parent’s name. В этом случае все члены уровня Region1, содержащие названия стран, будут скрыты (рис. 7).
Рис. 7. Несбалансированная иерархия
Именно для этого мы и создавали представление в хранилище данных — строка «Other», вполне устраивавшая нас при обращении к самому хранилищу данных, будучи именем члена измерения, не может выступать в качестве условия его скрытия.
Следующее измерение, которое мы создадим, будет основано на таблице Employee_Dim хранилища данных. Обычно измерения, содержащие сведения об административной подчиненности сотрудников, содержат еще один тип несбалансированных иерархий — иерархии типа «родитель-потомок» (parent-child). Такие иерархии нередко основаны на таблицах, где первичный ключ является одновременно и внешним ключом. Исходная таблица Employees базы данных Northwind действительно содержит сведения об административной подчиненности сотрудников (и имеет соответствующий внешний ключ), а таблица Employee_Dim — нет. Поэтому в первую очередь модифицируем ее, добавив к ней поле Reports_To:
ALTER TABLE dbo.Employee_Dim ADD Reports_To int
Затем с помощью DTS добавим в это поле данные из таблицы Employees (рис. 8).
Рис. 8. Добавление данных в таблицу Employee_Dim
Теперь можно создать измерение на основе таблицы Employee_Dim с помощью Dimension Wizard. В его первой диалоговой панели выберем опцию Parent-Child: Two related columns in a single dimension table. Далее опишем связь между двумя полями таблицы Employee_Dim, указав имя поля EmployeeID в качестве свойства Member_Key создаваемого измерения, Reports_To — в качестве его свойства Parent_Key, EmployeeName — в качестве его свойства Member Name (рис. 9).
Рис. 9. Определение параметров иерархии «родитель-потомок»
В диалоговой панели Select advanced options следует выбрать опцию Members with data, а в панели Set members with data property — опции Nonleaf members have associated data и Data members are visible. Это позволит анализировать как собственные результаты работы сотрудников, имеющих подчиненных, так и результаты работы их подчиненных. Создадим иерархию в этом измерении, назвав ее Employee.PC, и укажем в качестве свойства члена измерения поле Hire Date. В результате мы получим иерархию, показанную на рис. 10.
Рис. 10. Иерархия «родитель-потомок»
В качестве альтернативы создадим еще одну иерархию — Employee.Regular, содержащую один уровень Employee_Name; в качестве свойств члена этого уровня выберем поля Hire Date и Reports_To.
На этом мы закончим создание коллективных измерений и приступим к созданию куба.
Как и измерение, куб можно создать с помощью соответствующего мастера или непосредственно в редакторе кубов. В качестве примера создадим куб, основанный на нашем хранилище данных Northwind_Mart и использующий созданные выше измерения. Запустить мастер создания кубов можно командой New Cube | Wizard из контекстного меню элемента Cubes.
Первое, что следует сделать после запуска мастера, — выбрать таблицу фактов для будущего куба. В нашем случае это таблица Sales_Fact. Далее из таблицы фактов следует выбрать одно или несколько полей, на основе которых вычисляются меры куба (то есть поля, данные которых подлежат суммированию либо обработке с помощью других агрегатных функций). Выберем поля Line Item Total, Line Item Quantity и Line Item Discount (рис. 11).
Рис. 11. Выбор мер куба
Следующим шагом будет выбор коллективных измерений, используемых в этом кубе, а также создание недостающих частных измерений. Выберем коллективные измерения Employee.PC, Employee.Regular, Time.YQMD, Product и Customer. Кроме того, добавим новое измерение Shipper, нажав кнопку New Dimension в диалоговой панели выбора измерений. Это приведет к запуску уже знакомого нам мастера создания измерений; в последней из диалоговых панелей мастера в этом случае мы можем выбрать, каким будет создаваемое измерение — частным или коллективным (рис. 12).
Рис. 12. Выбор мер куба
Таким образом, мы определили метаданные куба. По окончании работы мастера будет запущен редактор кубов, в котором при необходимости можно внести исправления в определение куба, например добавить или удалить измерения и меры, создать вычисляемые значения и т.д. (рис. 13).
Рис. 13. Редактор кубов
Теперь попробуем добавить к нашему кубу вычисляемые значения, то есть значения, которые не хранятся в самом кубе, а вычисляются «на лету». Типичным примером такого значения может быть дополнительная мера, вычисленная на основе уже имеющихся. При вычислениях можно использовать как функции из библиотеки, входящей в состав Analysis Services, так и выражения VBA, а также собственные библиотеки функций (последние следует зарегистрировать в Analysis Services).
Для создания вычисляемых выражений следует выбрать раздел Calculated Members и из контекстного меню выбрать опцию New Сalculated Member. После этого будет запущен построитель выражений (Calculated Member Builder), в котором можно создавать и редактировать выражения, перетаскивая мышью имена измерений и их уровней, мер, имена функций. Например, перенесем в поле для выражения имена мер . и ., поставим между ними знак вычитания, а в качестве значения Member Name ведем Discounted Total (рис. 14).
Рис. 14. Редактор вычисляемых выражений
В результате мы получили еще одну меру — значение суммы, вырученной за товар, с учетом скидки.
Теперь можно сохранить определение куба, выбрав пункт меню File | Save редактора кубов.
Процесс создания куба на этом не завершен — мы создали его определение, но не производили никаких вычислений. Прежде чем произвести вычисления, напомним, что существует несколько способов хранения агрегатных данных (мы уже обсуждали эти способы в предыдущих статьях данного цикла). Для данного примера вполне подойдет хранение всех данных в многомерной базе данных (MOLAP), так как объем исходных данных невелик. Однако в других случаях следует оценить, какой способ хранения наиболее выгоден для данной задачи.
Еще один вопрос, который следует решить при создании многомерного хранилища данных — сколько агрегатов следует хранить? Агрегаты — это заранее вычисленные агрегатные данные, соответствующие ячейкам куба. Чем их больше, тем быстрее выполняются запросы к многомерному хранилищу и тем больше объем самого хранилища. Поэтому в общем случае требуется некое их количество, позволяющее осуществить разумный баланс между компактностью и производительностью.
Для определения количества агрегатов и их вычисления следует запустить Storage Design wizard — мастер создания многомерного хранилища. Для этого в редакторе кубов следует выбрать пункт меню Tools | Design Storage.
В первой диалоговой панели следует указать способ хранения данных — MOLAP, ROLAP или HOLAP (в нашем примере мы выберем MOLAP). Затем выбрать, какова должна быть производительность при выполнении запросов (либо будущий максимальный объем хранилища). После этого можно нажать на кнопку Start и получить зависимость производительности от объема хранилища (рис. 15).
Рис. 15. Определение количества агрегатов
И наконец, нам необходимо вычислить сами агрегатные данные. Это можно сделать как в том же мастере создания хранилища, так и в редакторе кубов (команда Tools | Process Cube, рис. 16).
Рис. 16. Вычисление агрегатных данных
Теперь, когда куб готов, можно заняться его просмотром в редакторе кубов (для этого нужно выбрать закладку Data в нижней части экрана, рис. 17).
Рис. 17. Просмотр сечений куба
В редакторе кубов мы можем просматривать различные двухмерные сечения куба, перемещая имена измерений на горизонтальную и вертикальную оси, а также скрывая и раскрывая уровни. Это самый простой из способов просмотра кубов. О других способах чтения многомерных кубов мы расскажем в одной из следующих статей данного цикла.
Заключение
В данной статье мы рассмотрели процесс создания многомерных баз данных Microsoft Analysis Services и содержащихся в них объектов. Мы узнали, что:
- в многомерных базах данных содержится несколько типов объектов, в том числе кубы и коллективные измерения;
- в Microsoft Analysis Services измерения делятся на коллективные и частные. Коллективные измерения могут быть использованы одновременно в нескольких кубах, а частные — принадлежат конкретному кубу.
Мы также научились создавать измерения с различными типами иерархий и узнали, что:
- иерархии в измерениях могут быть сбалансированными и несбалансированными. Несбалансированные иерархии обычно базируются на скрытии членов измерения, содержащих избыточные сведения;
- иерархии типа «родитель-потомок» обычно основаны на таблицах, чей первичный ключ является внешним ключом;
- можно создать несколько иерархий, используя одни и те же данные.
Кроме того, мы обсудили создание многомерных кубов и теперь знаем, что:
- при создании куба из таблицы фактов следует выбрать одно или несколько полей, на основе которых вычисляются меры куба, выбрать коллективные измерения, которые будут использоваться в этом кубе, а также создать недостающие частные измерения. При необходимости можно добавить к кубу вычисляемые значения;
- агрегаты — это заранее вычисленные агрегатные данные, соответствующие ячейкам куба. Чем их больше, тем быстрее выполняются запросы к многомерному хранилищу и тем больше объем самого хранилища;
- для вычисления агрегатных данных следует оценить, какой способ хранения наиболее выгоден для данной задачи, и определить на основе баланса производительности и объема хранилища, какое количество агрегатов следует создать;
- после вычисления агрегатных данных куба можно просматривать его двухмерные сечения в редакторе кубов.
Следующая статья данного цикла будет посвящена работе с Microsoft Excel как c OLAP-клиентом.
| Обсудить на форуме | Написать вебмастеру |