Содержание
- Соединение таблиц в языке запросов 1с
- Мы будем получать данные об ассоциациях людей, беря за основу цвет.
- Перекрёстное соединение в запросах 1С.
- Внутреннее соединение в запросах 1С.
- Левое соединение в запросах 1С.
- Правое соединение в запросах 1С.
- Полное соединение в запросах 1С.
- Анализ запросов с помощью SQL Profiler
- Момент Времени и Граница, назначение, примеры использования
Соединение таблиц в языке запросов 1с
Admin 1 апреля, 2020
Заметил на собеседованиях, что многие программисты путаются в соединении таблиц в языке запросов и не всегда точно, а тем более уверенно могут показать результат простого соединения. Сегодня в этой заметки разберем не сложные примеры соединения таблиц в запросах. Надеюсь данная статья поможем раз и навсегда разобраться в этом не сложной задаче, которая используется повсеместно в программировании.
Итак, имеем две таблицы ‘Рыбы’ и ‘ОбитаниеРыб’:
 Таблицы для соединения в запросе.
Таблицы для соединения в запросе.
ЛЕВОЕ СОЕДИНЕНИЕ: Данные из ‘левой’ таблицы выбираются в полном объеме, а из присоединяемой таблицы (‘правая’), только те записи, которые удовлетворяют условию соединения.
Пример: с условием ПО (ИСТИНА)
1С (Код)
| 1 2 3 4 5 6 7 8 9 10 | ТекстЗапроса = «ВЫБРАТЬ | Рыбы.Наименование КАК Наименование, | ОбитаниеРыб.Наименование КАК Наименование1, | ОбитаниеРыб.МестоОбитания КАК МестоОбитания, | ОбитаниеРыб.Цена КАК Цена, | ОбитаниеРыб.ID КАК ID |ИЗ | Справочник.Рыбы КАК Рыбы | ЛЕВОЕ СОЕДИНЕНИЕ Справочник.ОбитаниеРыб КАК ОбитаниеРыб | ПО (ИСТИНА)»; |
 ЛЕВОЕ СОЕДИНЕНИЕ – с условием ПО (ИСТИНА).
ЛЕВОЕ СОЕДИНЕНИЕ – с условием ПО (ИСТИНА).
Пример: с условием ПО (Рыбы.Наименование = ОбитаниеРыб.Наименование):
1С (Код)
| 1 2 3 4 5 6 7 8 9 10 | ТекстЗапроса = «ВЫБРАТЬ | Рыбы.Наименование КАК Наименование, | ОбитаниеРыб.Наименование КАК Наименование1, | ОбитаниеРыб.МестоОбитания КАК МестоОбитания, | ОбитаниеРыб.Цена КАК Цена, | ОбитаниеРыб.ID КАК ID |ИЗ | Справочник.Рыбы КАК Рыбы | ЛЕВОЕ СОЕДИНЕНИЕ Справочник.ОбитаниеРыб КАК ОбитаниеРыб | ПО Рыбы.Наименование = ОбитаниеРыб.Наименование»; |
 ЛЕВОЕ СОЕДИНЕНИЕ – с условием ПО (Рыбы.Наименование = ОбитаниеРыб.Наименование).
ЛЕВОЕ СОЕДИНЕНИЕ – с условием ПО (Рыбы.Наименование = ОбитаниеРыб.Наименование).
Пустые значения из правой таблицы – это отсутствующие значения (NUL).
Пример: с двойным условием связи ПО (Рыбы.Наименование = ОбитаниеРыб.Наименование) И Рыбы.ID = ОбитаниеРыб.ID:
1С (Код)
| 1 2 3 4 5 6 7 8 9 10 11 | ТекстЗапроса = «ВЫБРАТЬ | Рыбы.Наименование КАК Наименование, | ОбитаниеРыб.Наименование КАК Наименование1, | ОбитаниеРыб.МестоОбитания КАК МестоОбитания, | ОбитаниеРыб.Цена КАК Цена, | ОбитаниеРыб.ID КАК ID |ИЗ | Справочник.Рыбы КАК Рыбы | ЛЕВОЕ СОЕДИНЕНИЕ Справочник.ОбитаниеРыб КАК ОбитаниеРыб | ПО Рыбы.Наименование = ОбитаниеРыб.Наименование | И Рыбы.ID = ОбитаниеРыб.ID»; |
 ЛЕВОЕ СОЕДИНЕНИЕ – с двойным условием связи ПО (Рыбы.Наименование = ОбитаниеРыб.Наименование) И Рыбы.ID = ОбитаниеРыб.ID.
ЛЕВОЕ СОЕДИНЕНИЕ – с двойным условием связи ПО (Рыбы.Наименование = ОбитаниеРыб.Наименование) И Рыбы.ID = ОбитаниеРыб.ID.
ВНУТРЕННЕЕ СОЕДИНЕНИЕ: выводятся только те данные из двух таблиц, которые полностью совпали по условию.
Пример: с условием ПО (ИСТИНА):
1С (Код)
| 1 2 3 4 5 6 7 8 9 10 | ТекстЗапроса = «ВЫБРАТЬ | Рыбы.Наименование КАК Наименование, | ОбитаниеРыб.Наименование КАК Наименование1, | ОбитаниеРыб.МестоОбитания КАК МестоОбитания, | ОбитаниеРыб.Цена КАК Цена, | ОбитаниеРыб.ID КАК ID |ИЗ | Справочник.Рыбы КАК Рыбы | ВНУТРЕННЕЕ СОЕДИНЕНИЕ Справочник.ОбитаниеРыб КАК ОбитаниеРыб | ПО (ИСТИНА)»; |
 ВНУТРЕННЕЕ СОЕДИНЕНИЕ – с условием ПО (ИСТИНА).
ВНУТРЕННЕЕ СОЕДИНЕНИЕ – с условием ПО (ИСТИНА).
Пример: с условием ПО (Рыбы.Наименование = ОбитаниеРыб.Наименование):
1С (Код)
| 1 2 3 4 5 6 7 8 9 10 | ТекстЗапроса = «ВЫБРАТЬ | Рыбы.Наименование КАК Наименование, | ОбитаниеРыб.Наименование КАК Наименование1, | ОбитаниеРыб.МестоОбитания КАК МестоОбитания, | ОбитаниеРыб.Цена КАК Цена, | ОбитаниеРыб.ID КАК ID |ИЗ | Справочник.Рыбы КАК Рыбы | ВНУТРЕННЕЕ СОЕДИНЕНИЕ Справочник.ОбитаниеРыб КАК ОбитаниеРыб | ПО Рыбы.Наименование = ОбитаниеРыб.Наименование»; |
 ВНУТРЕННЕЕ СОЕДИНЕНИЕ – с условием ПО (Рыбы.Наименование = ОбитаниеРыб.Наименование).
ВНУТРЕННЕЕ СОЕДИНЕНИЕ – с условием ПО (Рыбы.Наименование = ОбитаниеРыб.Наименование).
ПРАВОЕ СОЕДИНЕНИЕ: это по сути тоже самое левое соединение, только присоединение будут идти к таблице с права. Если поменять таблицы местами, то получится левое соединение. Конструктор запроса автоматически правое соединение переделает в левое, поменяв таблицы местами. SQL также построит свой запрос через левое соединение.
Пример: с условием ПО (Рыбы.Наименование = ОбитаниеРыб.Наименование):
1С (Код)
| 1 2 3 4 5 6 7 8 9 10 | ТекстЗапроса = «ВЫБРАТЬ | Рыбы.Наименование КАК Наименование, | ОбитаниеРыб.Наименование КАК Наименование1, | ОбитаниеРыб.МестоОбитания КАК МестоОбитания, | ОбитаниеРыб.Цена КАК Цена, | ОбитаниеРыб.ID КАК ID |ИЗ | Справочник.Рыбы КАК Рыбы | ПРАВОЕ СОЕДИНЕНИЕ Справочник.ОбитаниеРыб КАК ОбитаниеРыб | ПО (Рыбы.Наименование = ОбитаниеРыб.Наименование)»; |
 ПРАВОЕ СОЕДИНЕНИЕ – с условием ПО (Рыбы.Наименование = ОбитаниеРыб.Наименование).
ПРАВОЕ СОЕДИНЕНИЕ – с условием ПО (Рыбы.Наименование = ОбитаниеРыб.Наименование).
ПОЛНОЕ СОЕДИНЕНИЕ: выводит записи из двух таблиц при этом соединяя те, которые полностью подошли по условию.
Пример: с условием ПО (Рыбы.Наименование = ОбитаниеРыб.Наименование):
1С (Код)
| 1 2 3 4 5 6 7 8 9 10 | ТекстЗапроса = «ВЫБРАТЬ | Рыбы.Наименование КАК Наименование, | ОбитаниеРыб.Наименование КАК Наименование1, | ОбитаниеРыб.МестоОбитания КАК МестоОбитания, | ОбитаниеРыб.Цена КАК Цена, | ОбитаниеРыб.ID КАК ID |ИЗ | Справочник.Рыбы КАК Рыбы | ПОЛНОЕ СОЕДИНЕНИЕ Справочник.ОбитаниеРыб КАК ОбитаниеРыб | ПО Рыбы.Наименование = ОбитаниеРыб.Наименование»; |
 ПОЛНОЕ СОЕДИНЕНИЕ – с условием ПО (Рыбы.Наименование = ОбитаниеРыб.Наименование).
ПОЛНОЕ СОЕДИНЕНИЕ – с условием ПО (Рыбы.Наименование = ОбитаниеРыб.Наименование).
Так же в запросе можно сделать и перекрёстное соединение таблиц (не используя закладку ‘связи’):
1С (Код)
| 1 2 3 4 5 6 7 8 9 10 | ТекстЗапроса = «ВЫБРАТЬ | Рыбы.Наименование КАК Наименование, | Рыбы.ID КАК ID, | ОбитаниеРыб.Наименование КАК Наименование1, | ОбитаниеРыб.МестоОбитания КАК МестоОбитания, | ОбитаниеРыб.Цена КАК Цена, | ОбитаниеРыб.ID КАК ID1 |ИЗ | Справочник.Рыбы КАК Рыбы, | Справочник.ОбитаниеРыб КАК ОбитаниеРыб»; |
Перекрёстное соединение.
Понимание принципа соединения таблиц в 1с поможет вам вытащить из базы данных всю необходимую информацию!
Ну и небольшая подсказка для новичков:
ВНУТРЕННЕЕ соединение. ПОЛНОЕ соединение. ЛЕВОЕ соединение. ПРАВОЕ соединение (перейдет в левое автоматически). 4+
Соединения в запросах 1С, пожалуй, наиважнейшая операция с таблицами базы данных. Именно от корректности применения нужного соединения, в каждом конкретном случае, зависят получаемые итоговые данные из базы.
При помощи соединений, мы сопоставляем записи одной таблицы, с записями другой. Прежде чем приступить к рассмотрению соединений, подготовим небольшую базу данных. (Демонстрационную базу данных можно скачать внизу страницы.)
Итак, мы имеем несколько справочников, а именно:
Справочник “Люди”.
Справочник “Цвета”.
Справочник “Ассоциации”.
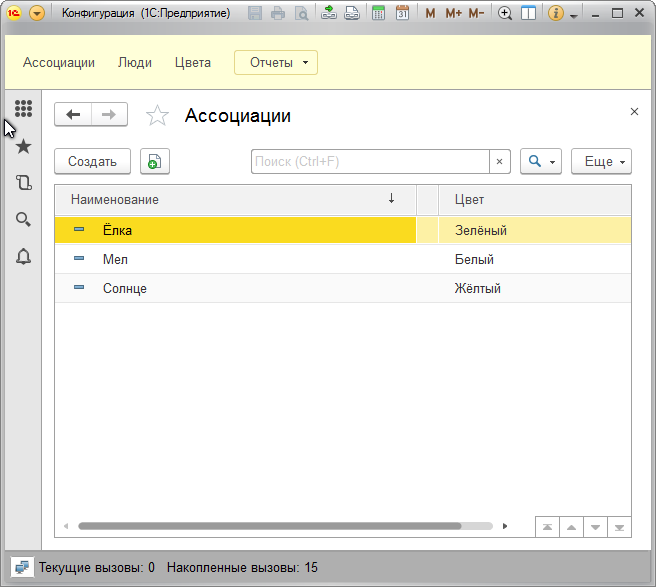
Мы будем получать данные об ассоциациях людей, беря за основу цвет.
К примеру, для Ольги ассоциацией будет трава, так как она предпочитает зелёный цвет. Для Александра и Василия, подходящих им ассоциаций, нет, по причине того, что они предпочитают синий и красный цвета. А вот ассоциаций для этих цветов, в базе не указано. Нужно ещё обратить внимание, что белый цвет никто не предпочитает, хотя в базе он указан и ассоциация ему – мел. Запомните это, дальше эти сведения нам пригодятся.
Давайте получим имена людей, с предпочитаемыми ими, цветами.
| 1 2 3 4 5 | ВЫБРАТЬ Люди.Наименование КАК Наименование, Люди.ПредпочитаетЦвет КАК ПредпочитаетЦвет ИЗ Справочник.Люди КАК Люди |
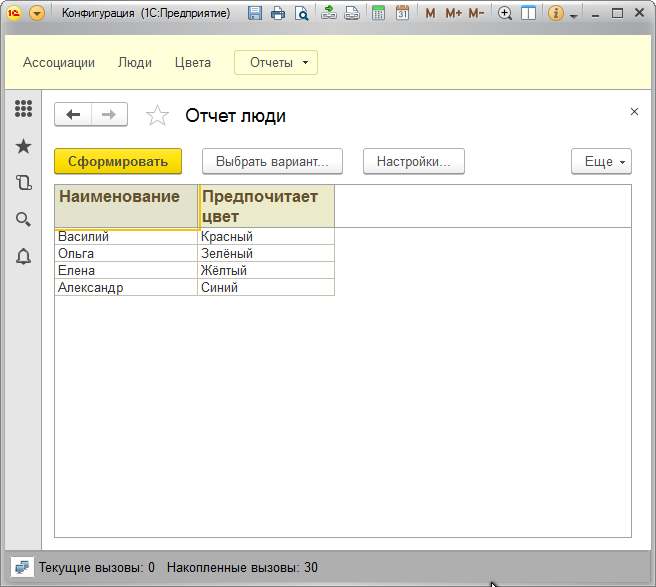
Теперь получим ассоциации с их цветами.
| 1 2 3 4 5 | ВЫБРАТЬ Ассоциации.Наименование КАК Наименование, Ассоциации.Цвет КАК Цвет ИЗ Справочник.Ассоциации КАК Ассоциации |
Перекрёстное соединение в запросах 1С.
Выполним перекрёстное соединение. Здесь мы получим получим все записи из всех таблиц.
| 1 2 3 4 5 6 7 8 | ВЫБРАТЬ Люди.Наименование КАК Наименование, Люди.ПредпочитаетЦвет КАК ПредпочитаетЦвет, Ассоциации.Наименование КАК Наименование1, Ассоциации.Цвет КАК Цвет ИЗ Справочник.Люди КАК Люди, Справочник.Ассоциации КАК Ассоциации |
Как видите, никакой информативности.
Внутреннее соединение в запросах 1С.
Всё же, давайте получим интересующие нас результаты, где значение предпочитаемого цвета, равно значению цвета ассоциации. Для этого, нам нужно добавить к запросу, конструкцию ГДЕ.
| 1 2 3 4 5 6 7 8 9 10 | ВЫБРАТЬ Люди.Наименование КАК Наименование, Люди.ПредпочитаетЦвет КАК ПредпочитаетЦвет, Ассоциации.Наименование КАК Наименование1, Ассоциации.Цвет КАК Цвет ИЗ Справочник.Люди КАК Люди, Справочник.Ассоциации КАК Ассоциации ГДЕ Люди.ПредпочитаетЦвет = Ассоциации.Цвет |
Ещё один вариант внутреннего соединения, в котором конструкция ГДЕ не применяется. Вместо неё, мы укажем в запросе, само выражение ВНУТРЕННЕЕ СОЕДИНЕНИЕ.
| 1 2 3 4 5 6 7 8 9 | ВЫБРАТЬ Люди.Наименование КАК Наименование, Люди.ПредпочитаетЦвет КАК ПредпочитаетЦвет, Ассоциации.Наименование КАК Наименование1, Ассоциации.Цвет КАК Цвет ИЗ Справочник.Люди КАК Люди ВНУТРЕННЕЕ СОЕДИНЕНИЕ Справочник.Ассоциации КАК Ассоциации ПО Люди.ПредпочитаетЦвет = Ассоциации.Цвет |
Как видите, в том и другом случае, полученные нами данные, абсолютно идентичны.
Схематично:
Левое соединение в запросах 1С.
Как видно из предыдущего запроса, в результирующие данные не попали Василий и Александр, по причине того, что они предпочитают синий и красный цвета. А ассоциаций для этих цветов, в нашей базе данных нет.
Нам необходимо переписать запрос так, чтобы эти люди, всё же, были представлены в результатах, не смотря на то, что для их любимых цветов, ассоциации не сопоставлены.
| 1 2 3 4 5 6 7 8 9 | ВЫБРАТЬ Люди.Наименование КАК Наименование, Люди.ПредпочитаетЦвет КАК ПредпочитаетЦвет, Ассоциации.Наименование КАК Наименование1, Ассоциации.Цвет КАК Цвет ИЗ Справочник.Люди КАК Люди ЛЕВОЕ СОЕДИНЕНИЕ Справочник.Ассоциации КАК Ассоциации ПО Люди.ПредпочитаетЦвет = Ассоциации.Цвет |
Левое соединение представляет из себя:
Схематично:
Правое соединение в запросах 1С.
Давайте ещё раз взглянем на внутреннее соединение:
Как видно, здесь отсутствует ассоциация Мел с белым цветом, так как этот цвет никто из наших людей не предпочитает.
Нам необходимо переписать запрос так, чтобы мы получили записи из второй таблицы, которые не имеют пар (не сопоставлены) с первой.
| 1 2 3 4 5 6 7 8 9 | ВЫБРАТЬ Люди.Наименование КАК Наименование, Люди.ПредпочитаетЦвет КАК ПредпочитаетЦвет, Ассоциации.Наименование КАК Наименование1, Ассоциации.Цвет КАК Цвет ИЗ Справочник.Люди КАК Люди ПРАВОЕ СОЕДИНЕНИЕ Справочник.Ассоциации КАК Ассоциации ПО Люди.ПредпочитаетЦвет = Ассоциации.Цвет |
Правое соединение представляет из себя:
Схематично:
Полное соединение в запросах 1С.
А теперь представим, что возникла необходимость получить все записи из двух таблиц. Независимо от того, есть ли у них сопоставленные пары или нет. Для этой цели, нам нужно будет совместить результаты левого и правого соединений. Как раз для таких случаев существует полное соединение.
| 1 2 3 4 5 6 7 8 9 | ВЫБРАТЬ Люди.Наименование КАК Наименование, Люди.ПредпочитаетЦвет КАК ПредпочитаетЦвет, Ассоциации.Наименование КАК Наименование1, Ассоциации.Цвет КАК Цвет ИЗ Справочник.Люди КАК Люди ПОЛНОЕ СОЕДИНЕНИЕ Справочник.Ассоциации КАК Ассоциации ПО Люди.ПредпочитаетЦвет = Ассоциации.Цвет |
Полное соединение представляет из себя:
Схематично:
Как видно выше, некоторые поля у нас пустые. На самом деле эти данные являются очень коварными значениями NULL. NULL означает отсутствие значения, любая операция с ним приведёт к ошибке. Даже, если сравнить NULL с NULL, результатом этого сравнения будет Ложь. Не даром, во всех конфигурациях, в обязательном порядке, требуется проводить обработку такого значения, в местах возможного его возникновения.
Мы так же, не оставим это без внимания и в запросе с полным соединением, применим функцию ЕСТЬNULL. Эта функция проверяет результаты запроса на NULL и если, она получает такое значение, то возвращает другое значение, указанное нами в параметрах этой функции.
Демонстрационная база данных Обзор Видов Соединений
Другие статьи по оптимизации 1С:
«Как ускорить 1С – Многопоточная обработка данных»
«Как ускорить 1С за 5 минут – Протокол Shared Memory»
«3 главных вопроса про временные таблицы 1С»
Анализ запросов с помощью SQL Profiler
Что Вы узнаете из этой статьи?
- Предназначение инструмента трассировки SQL Profiler
- Как отследить текст запроса к СУБД, в который транслируется запрос 1С
- Настройки фильтров трассировки
- Как выполнить персональную настройку SQL Profiler
Зачастую в работе возникает ситуация, когда запрос в 1С по каким-то причинам работает медленно, но анализ текста запроса не говорит нам о каких-либо проблемах.
В таком случае приходится изучать эту проблему на более низком уровне. Для этого нам нужно посмотреть текcт SQL-запроса и план запроса. Для этого можно использовать SQL Profiler.
SQL Profiler – предназначение
SQL Profiler – это программа, входящая в MS SQL Server, которая предназначена для просмотра всех событий, которые происходят в SQL-сервере. Иначе говоря, она нужна для записи трассировки.
В каких случаях данный инструмент может быть полезен 1С программисту? Прежде всего, можно получить текст запроса на языке SQL и посмотреть его план. Это также можно сделать и в технологическом журнале (ТЖ), но план запроса в ТЖ получается не таким удобным и требует наличия некоторых навыков и умений. К тому же в профайлере можно посмотреть не только текстовый, но и графический план выполнения запроса, что является более удобным.
Также профайлер позволяет узнать:
- запросы длиннее определенного времени
- запросы к определенной таблице
- ожидания на блокировках
- таймауты
- взаимоблокировки и т. д.
Зачастую Profiler применяется именно для анализа запросов. И при этом нужно анализировать не все исполняемые запросы, а то, как определенный запрос на языке 1С транслируется в SQL, и обращать внимание на его план выполнения.
В частности, это бывает необходимо, чтобы понять, почему запрос выполняется медленно. Или при построении большого и сложного запроса необходимо удостовериться, что запрос на языке SQL не содержит соединений с подзапросом.
Для отслеживания запроса в трассировке выполняем следующие шаги:
1. Запускаем SQL Profiler: Пуск — Все программы — Microsoft SQL Server 2008 R2 — Средства обеспечения производительности — SQLProfiler.
2. Создаем новую трассировку: Файл – Создать трассировку (Ctrl+N).
3. Указываем сервер СУБД, на котором находится наша база данных и нажимаем Соединить:
Нам ничто не мешает выполнять трассировку сервера СУБД, находящегося на любом другом компьютере.
4. В появившемся окне Свойства трассировки переключаемся на закладку Выбор событий:
5. Далее нужно указать события и их свойства, которые мы хотим видеть в трассировке.
Так как нам нужны запросы и планы запросов, то необходимо включить соответствующие события. Для показа полного списка свойств и событий включаем флаги Показать все события и Показать все столбцы. Теперь необходимо выбрать только события, приведенные на рисунке ниже, остальные же – требуется отключить:
Описание этих событий:
- ShowplanStatisticsProfile– текстовый план выполнения запроса
- ShowplanXMLStatisticsProfile– графический план выполнения запроса
- RPC:Completed– текст запроса, если он выполняется как процедура (если выполняется запрос 1С с параметрами)
- SQL:BatchCompleted– текст запроса, если он выполняется как обычный запрос (если выполнялся запрос 1С без параметров)
6. На этом этапе необходима настройка фильтра для выбранных событий. Если фильтр не установлен, то мы будем видеть запросы для всех БД, расположенных на данном сервере СУБД. По кнопке Фильтры столбцов устанавливаем фильтр по имени базы данных:
Теперь мы видим в трассировке только запросы к БД «TestBase_8_2».
Также можно поставить фильтр и по другим полям, наиболее интересные из них:
- Duration (длительность)
- TextData (обычно это текст запроса)
- RowCounts (количество строк, возвращаемых запросом)
Допустим, нам необходимо «отловить» все запросы к таблице «_InfoRg4312» длительностью более 3-х секунд в базе данных «TestBase_8_2». Для этого необходимо:
a) Установить фильтр по базе данных (см. выше)
b) Установить фильтр по длительности (устанавливается в миллисекундах):
c) Установить фильтр по тексту запроса:
Для задания фильтра по тексту запроса используем маску. В случае необходимости отслеживать запросы, которые обращаются к нескольким таблицам, создается несколько элементов в разделе «Похоже на». Наложенные условия фильтров работают совместно.
7. Теперь запускаем трассировку с помощью кнопки Запустить в окне Свойства трассировки и наблюдаем события, попадающие под установленные фильтры, отображение которых было настроено.
Кнопки командной панели служат для управления трассировкой:
Назначение кнопок:
- Ластик – очищает окно трассировки
- Пуск – запускает трассировку
- Пауза – ставит трассировку на паузу, при нажатии на Пуск трассировка возобновляется
- Стоп – останавливает трассировку
8. Окно трассировки состоит из двух частей. В верхней части находятся события и их свойства, в нижней – информация, зависящая от типа событий. Для нашего примера здесь будет отображаться либо текст запроса, либо его план.
9. Запустим на выполнение запрос в консоли запросов 1С и посмотрим, как он отразится в профайлере:
По поведению трассировки видно, что запросов в итоге получилось несколько, и только один из них нам интересен. Остальные запросы – служебные.
10. Свойства событий дают возможность оценить:
- сколько секунд выполнялся запрос (Duration)
- сколько было логических чтений (Reads)
- сколько строк запрос вернул в результате (RowCounts) и т.д.
В нашем случае запрос выполнялся 2 миллисекунды, сделал 4 логических чтения и вернул 1 строку.
11. Если взглянуть на одно событие выше, то можно увидеть план запроса в графическом виде:
Из плана видно, что поиск осуществляется по индексу по цене, этот план нельзя назвать идеальным, так как индекс не является покрывающим, поля код и наименование получаются с помощью KeyLookup, что отнимает 50% времени.
Используя контекстное меню, полученный графический план запроса возможно сохранить в отдельный файл с расширением *.SQLPlan и открыть его в профайлере на другом компьютере или с помощью программы SQL Sentry Plan Explorer, которая является более продвинутой.
12. Если подняться еще выше, то мы увидим тот же план запроса, но уже в текстовом виде. Именно этот план отображается в ТЖ, ЦУП и прочих средствах контроля производительности 1С.
{kind=link}
13. Через меню Файл – Сохранить как можно сохранить всю трассировку в различные форматы:
- В формат самого профайлера, то есть с расширением *.trc
- В формат xml
- Сделать из трассировки шаблон (См. следующий пункт)
- Cохранить полученную трассировку в виде таблицы базы данных. Это весьма удобный способ, когда, к примеру, нужно найти самый медленный запрос в трассировке или отфильтровать запросы по какому-либо параметру.
Используем меню Файл – Сохранить как – Таблица трассировки – Выбираем сервер СУБД и подключаемся к нему.
Затем выбираем базу данных на указанном сервере, указываем имя таблицы, куда будет сохранена трассировка. Можно использовать существующую таблицу, или дать ей новое имя, и тогда эта таблица будет создана автоматически.
Теперь возможно строить запросы любой сложности к нашей таблице: к примеру, искать наиболее долго выполняющиеся запросы.
Также нужно помнить, что Duration сохраняется в таблицу в миллионных долях секунды, и при выводе результата нужно переводить значение в миллисекунды. Также в таблице присутствует столбец RowNumber, показывающий номер данной строки в трассировке.
14. При частом использовании профайлера для анализа запросов постоянная настройка нужных событий и фильтров будет постоянно отнимать у вас много времени.
В данном случае нам помогут шаблоны трассировок, где мы настраиваем нужные нам фильтры и порядок колонок, а далее просто используем уже имеющийся шаблон при создании новой трассировки.
Для создания шаблона используем меню Файл – Шаблоны – Новый шаблон:
На первой закладке указываем тип сервера, имя шаблона и при необходимости ставим флаг для использования данного шаблона по умолчанию.
На второй закладке делаем выбор нужных событий и осуществляем настройку фильтров (как было показано выше).
Дополнительно рекомендуется выполнить настройку порядка столбцов в трассировке, что экономит время при последующем анализе запросов. Удобным представляется следующий порядок:
При создании новой трассировки можем указать нужный шаблон, и тогда на второй закладке все фильтры и события заполнятся автоматически по созданному шаблону.
Бурмистров Андрей
PDF-версия статьи для участников группы ВКонтакте
Мы ведем группу ВКонтакте – http://vk.com/kursypo1c.
Если Вы еще не вступили в группу – сделайте это сейчас и в блоке ниже (на этой странице) появятся ссылка на скачивание материалов.
Ссылка доступна для зарегистрированных пользователей)
Ссылка доступна для зарегистрированных пользователей)
Ссылка доступна для зарегистрированных пользователей)
Если Вы уже участник группы – нужно просто повторно авторизоваться в ВКонтакте, чтобы скрипт Вас узнал. В случае проблем решение стандартное: очистить кеш браузера или подписаться через другой браузер. Станьте экспертом по оптимизации 1С, изучив наш курс
«Ускорение и оптимизация систем на 1С:Предприятие 8.3 (2016). Подготовка на 1С:Эксперт по технологическим вопросам»
Содержание курса и форма заказа: https://курсы-по-1с.рф/1c-v8/optimization/
35 учебных часов, подготовка к 1С:Эксперт, правильная настройка серверной части, оптимизация кода, мониторинг загруженности оборудования и прочие взрослые вещи.
Момент Времени и Граница, назначение, примеры использования
Момент времени:
Фирма 1С описывает так:
Предназначен для получения и хранения момента времени для объекта в базе данных. Содержит дату и время, а также ссылку на объект базы данных. Используется в качестве значений свойств и параметров методов других объектов, имеющих тип МоментВремени.
Момент времени используется в тех случаях, когда важно различать моменты времени для объектов, имеющих одинаковую дату и время, например для сравнения положений документов на временной оси.
А своими словами:
Момент времени — комбинация даты и ссылки на документ. Позволяет разделить и упорядочить документы в пределах одной секунды, выстраивая все документы в однозначную последовательность. Получение данных при проведении на момент времени гарантирует, что будут учтены движения сделанные в ту же секунду что и проводимый документ, но находящиеся перед ним.
Но есть особенность — документы проведенные в одну и ту же секунду располагаются в произвольном порядке, а не в порядке их физического создания (как было в 7.7).
МоментВремени() — это момент непосредственно ПЕРЕД позицией документа (аналог РассчитатьРегистрыНа(ТекущийДокумент() в 7-рке), а если необходимо получить момент непосредственно после позиции документа, то используйте объект Граница
Код 1C v 8.х МоментСразуПослеДокумента = Новый Граница(ДокументСсылка,ВидГраницы.Включая)
Код 1C v 8.х // Пример создает момент времени по дате и ссылке на объект в базе данных.
Момент = Новый МоментВремени(ТекДокумент.Дата, ТекДокумент.Ссылка);
При получение остатков:
«Момент времени» — виртуальное поле, не хранится в базе данных. Содержит объект МоментВремени (который включает в себя ДАТУ и ССЫЛКУ НА ДОКУМЕНТ)
<Виртуальная> таблица остатков не хранится в БД, а строится в момент обращения к ней.
1. подбирается больший или равный значению ПАРАМЕТР момент времени, на который РАССЧИТАНЫ остатки
2. на этот момент получаются остатки из таблицы итогов
3. если момент времени, на который считаются остатки, не совпадает с моментом времени итогов, то остатки ДОСЧИТЫВАЮТСЯ по движениям.
Граница:
Предназначен для получения и хранения границы некоторого интервала значений. Содержит граничное значение интервала, а также признак включения или исключения граничного значения в интервал.
Используется в качестве значений свойств и параметров методов других объектов, имеющих тип Граница.
Граница используется в тех случаях, когда важно указание включения или исключения граничного значения, например при получении остатков и оборотов регистров накопления, срезов и значений регистров сведений, для задания интервалов запросов.
ВидГраницы — Определяет набор видов границ по отношению к граничному значению:
ВидГраницы.Включая — Граница включает граничное значение.
ВидГраницы.Исключая — Граница исключает граничное значение.
Код 1C v 8.х Граница = Новый Граница(Дата, ВидГраницы.Включая);
Запрос.УстановитьПараметр(«КонГраница», Граница);
Пример получения остатков на дату документа, включая его движения
Код 1C v 8.х Запрос = Новый Запрос;
Запрос.Текст =
«ВЫБРАТЬ
| ВзаиморасчетыСРаботникамиОрганизацийОстатки.Физлицо,
| ВзаиморасчетыСРаботникамиОрганизацийОстатки.СуммаВзаиморасчетовОстаток
|ИЗ
| РегистрНакопления.ВзаиморасчетыСРаботникамиОрганизаций.Остатки(&МомВрем, Физлицо = &Физик) КАК ВзаиморасчетыСРаботникамиОрганизацийОстатки»;
МомВрем = Документы.НачислениеЗарплатыРаботникамОрганизаций.НайтиПоНомеру(«00012″,»31.12.2009 23:59:59»);
Запрос.УстановитьПараметр(«МомВрем», Новый Граница(МомВрем.МоментВремени(), ВидГраницы.Включая));
Запрос.УстановитьПараметр(«Физик», Справочники.ФизическиеЛица.НайтиПоКоду(«365»));
ВывестиРезультат(Запрос.Выполнить());
Пример получения остатков на дату документа, но до его движений
Код 1C v 8.х Запрос = Новый Запрос;
Запрос.Текст =
«ВЫБРАТЬ
| ВзаиморасчетыСРаботникамиОрганизацийОстатки.Физлицо,
| ВзаиморасчетыСРаботникамиОрганизацийОстатки.СуммаВзаиморасчетовОстаток
|ИЗ
| РегистрНакопления.ВзаиморасчетыСРаботникамиОрганизаций.Остатки(&МомВрем, Физлицо = &Физик) КАК ВзаиморасчетыСРаботникамиОрганизацийОстатки»;
МомВрем = Документы.НачислениеЗарплатыРаботникамОрганизаций.НайтиПоНомеру(«00012″,»31.12.2009 23:59:59»);
Запрос.УстановитьПараметр(«МомВрем», Новый Граница(МомВрем.МоментВремени(), ВидГраницы.Исключая));
// или так: Запрос.УстановитьПараметр(«МомВрем», МомВрем.МоментВремени());
Запрос.УстановитьПараметр(«Физик», Справочники.ФизическиеЛица.НайтиПоКоду(«365»));
ВывестиРезультат(Запрос.Выполнить());
1. Вы просто индексы готовить не умеете, потому как у Вас поверхностные знания общих принципов применения и работы индексов на платформах БД. Вообще есть определенные стандарты, согласно которым проектировщики платформ БД (вменяемые) следуют, иначе спроса на их платформу не будет.
Так вот ответ на ваш вопрос — раз у вас в левом соединении временная таблица и по ней в самом запросе не идут поиск — значит у вас данные из левой таблицы выводятся в результат запроса (иначе зачем тогда Вам вообще левое соединение). А соответственно соединение по имеющимся записям в левой таблице может идти по ее (левой таблицы) индексу или по поиску (перебору) всех записей этой левой таблицы. И так по каждой строке правой. Да, если записей мало — то результат не так заметен, а то и даже… но когда записей много… Поймите — соединение, какое оно бы ни было — это соединение. И в данном случае можно всю таблицу перебирать, а можно по индексу сработать.
2. Если нужно получить максимально быстро результат выборки, особенно если многократно с этими временными таблицами — то обе. При соединении (не важно каком именно) платформа БД при наличии индекса на поле таблице — работает всегда по индексу. Это всегда быстрее.
3. Автор как раз понимает тему, это Вы не в теме и совершенно не представляете как работают индексы. Да, записей в индексе столько же будет, но принцип работы по индексу совершенно другой. Возможно, если у вас обе таблицы абсолютно аналогично отсортированы по полям соединения — то может и не такой эффект будет — но ведь это как правило не так…
В общем вывод — статью писали думая — это Вы ответили, не подумав…
Ответить